Crea tu API REST reactiva con Kotlin y Ktor Parte I

La programación reactiva tiene muchas aplicaciones, una de ella es poder aplicarse en cualquier parte del front y back para aprovecharse de algunas de sus ventajas. Este año también la hemos trabajado en clase. Como uno de los responsables del track de Kotlin Developer estoy escribiendo una serie de tutoriales para Hyperskill (opens new window) de Jetbrains Academy (opens new window), donde se explica como crear una API REST reactiva con Kotlin y Ktor y repaso una serie de conceptos en la que se basa. Os lo dejo traducido, pero recomiendo que leáis el original en inglés y votéis para que sigan saliendo más partes: Creating Your Reactive REST API with Kotlin and Ktor Part I (opens new window).
Sobre la traducción
Lamentablemente no tengo tiempo para traducir todos los artículos que escribo, pero este me pareció interesante y que podía aportar algo a la comunidad. Por ello, he usado ChatGPT y pulido los errores que me he encontrado. De nuevo te recomiendo la lectura del original en inglés si buscas el 100% de exactitud: Creating Your Reactive REST API with Kotlin and Ktor Part I (opens new window).
# Introducción
Una de las cosas esenciales que cualquier desarrollador de backend debe dominar es la creación de servicios REST.
En la actualidad, la gestión eficiente y efectiva de los recursos es una ventaja que debemos lograr. La programación reactiva nos ofrece soluciones para la demanda de tiempos de respuesta más rápidos y alta disponibilidad de los sistemas, características que se logran con modelos anteriores de microservicios, pero que dan soluciones a los problemas de uso excesivo de la CPU, bloqueo en operaciones de entrada y salida, o uso de memoria (debido a grandes grupos de subprocesos) de los que sufrían estos modelos.
A lo largo de esta serie de artículos, se presentan una serie de contenidos que aprenderás a través de las diferentes pistas de formación de Hyperskill (opens new window). Con Hyperskill podrás profundizar en ellos, ampliarlos, analizar diferentes alternativas y convertirte en un verdadero desarrollador de backend.
En estos tutoriales mostramos cómo configurar una API REST reactiva utilizando Ktor y Kotlin, analizando todos los elementos, utilizando la programación orientada a ferrocarriles, la inyección de dependencias, las pruebas y aplicando varias configuraciones de seguridad, autenticación y autorización hasta que puedas implementarlo y disfrutar de tus logros. Recuerda que este código es pedagógico y muestra muchos de los contenidos que aprenderás en Hyperskill de una manera didáctica y fácil de leer. No tiene la intención de crear el mejor código de producción en entornos reales.
# La Programación Reactiva
Siguiendo los principios del Manifiesto Reactivo (opens new window), los sistemas reactivos deben ser:
- Responsivos: El sistema responde de manera oportuna siempre que sea posible.
- Resilientes: El sistema se mantiene responsivo ante fallos.
- Elásticos: El sistema se mantiene responsivo bajo cargas de trabajo variables.
- Basados en mensajes: Los sistemas reactivos se basan en el paso de mensajes asincrónico para establecer una frontera entre componentes que garantiza un acoplamiento laxo, aislamiento y transparencia de ubicación.
La programación reactiva se centra en trabajar con flujos asíncronos de fuentes de datos finitas o infinitas donde podemos observarlos.

La programación reactiva es un subconjunto de la programación asíncrona. Permite descomponer el problema en múltiples pasos discretos en los que cada uno se puede ejecutar de manera asíncrona y no bloqueante, para luego componerlos y producir el flujo de trabajo final.
La programación reactiva ofrece varias ventajas, incluida una mejor utilización de los recursos informáticos en sistemas multinúcleo y multiprocesador, y un rendimiento mejorado al reducir los puntos de serialización. Otro beneficio importante es el aumento de la productividad del desarrollador. Los paradigmas de programación tradicionales han tenido dificultades para proporcionar una forma sencilla y mantenible de manejar la computación asíncrona y no bloqueante y las operaciones de entrada y salida. La programación reactiva resuelve la mayoría de estos desafíos al eliminar la necesidad de coordinación explícita entre los componentes activos.
Para aprovechar la ejecución asíncrona, es necesario incluir el control de retroalimentación para evitar la sobreutilización o el consumo desmedido de recursos. Por ejemplo, en las entradas y salidas con bases de datos que utilizan JDBC, bloqueamos el hilo hasta que recibimos una respuesta. Este es un ejemplo sencillo de las cosas que vamos a resolver para mejorar la productividad de nuestros servicios.
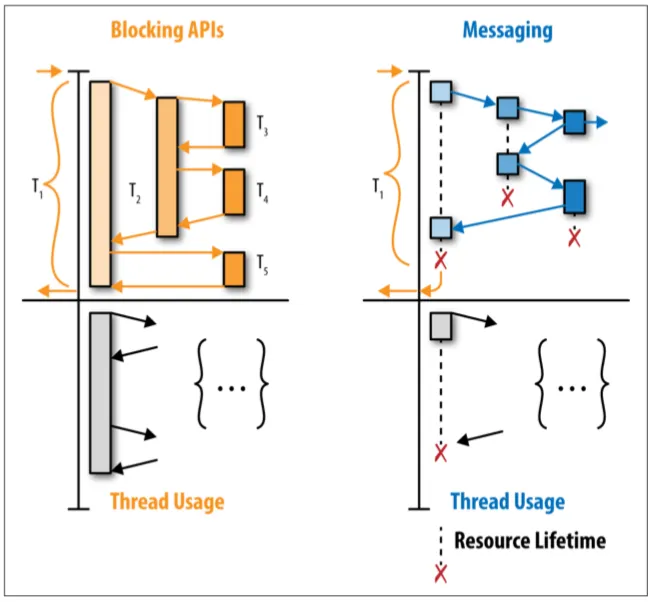
Aquí es donde Ktor (opens new window) y Kotlin (opens new window) forman un equipo invencible. Ktor nos ofrece la posibilidad de crear servicios asíncronos (primera condición), y Kotlin ofrece corrutinas (opens new window) y Flows (flujos) (opens new window) para procesar colecciones de manera asíncrona y reactiva.
# Creando un nuevo proyecto con Kotlin y Ktor
Kotlin es un lenguaje de programación de tipo estático que tiene varias ventajas sobre otros lenguajes de programación. Algunas de las ventajas de Kotlin son: interoperabilidad con Java, sintaxis concisa, seguridad ante valores nulos, soporte para programación funcional, funciones de extensión y coroutines, lo que facilita la escritura de código asíncrono y no bloqueante. Las coroutines son livianas y eficientes y se pueden utilizar para simplificar código asíncrono complejo. El soporte de Kotlin es una excelente elección para construir aplicaciones modernas.

Ktor es un framework ligero basado en Kotlin utilizado para crear aplicaciones y servicios web en el lado del servidor. Proporciona una API simple y flexible para construir aplicaciones asíncronas, basadas en eventos y no bloqueantes.
Con Ktor, los desarrolladores pueden crear fácilmente APIs RESTful, aplicaciones web y microservicios. Es un framework de código abierto que se puede utilizar para construir aplicaciones tanto web como móviles. Ktor se puede utilizar con coroutines y flows de Kotlin para escribir código asíncrono/reactivo de manera más concisa y legible.
Ktor utiliza plugins para ampliar su funcionalidad según las necesidades del proyecto. Algunos de ellos están incluidos por defecto, otros deben ser instalados. En ambos casos, debemos configurarlos para poder utilizarlos.

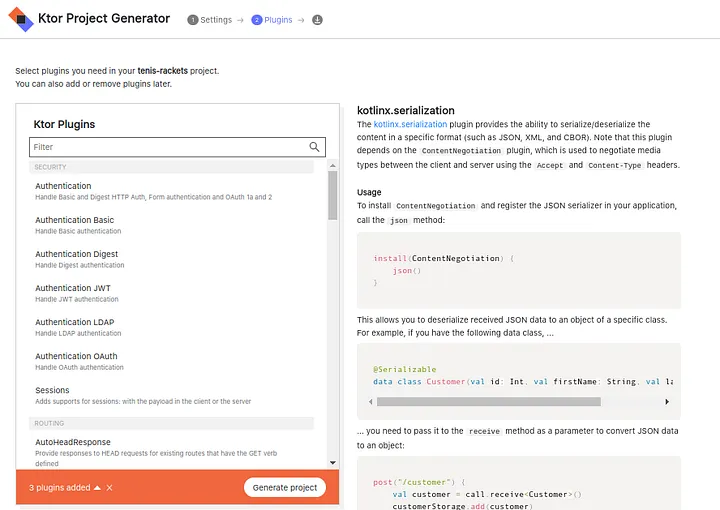
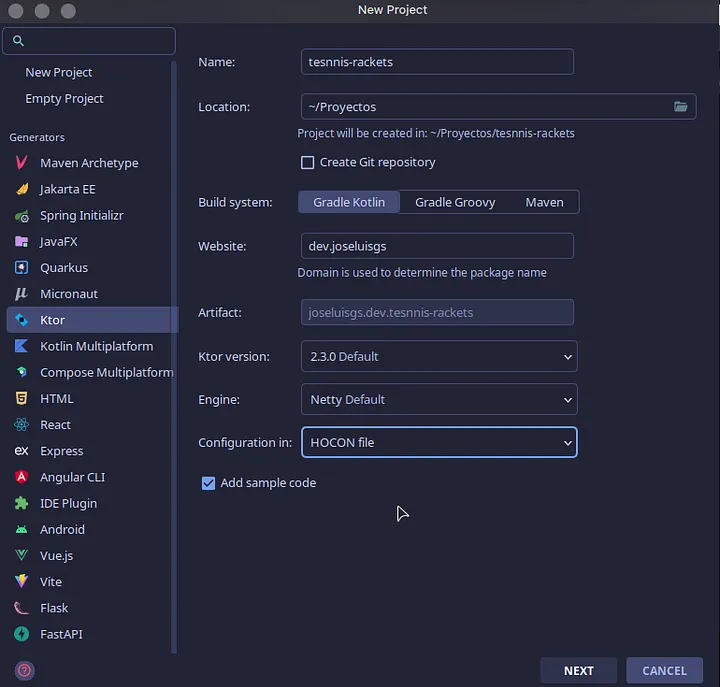
Podemos crear un proyecto Ktor desde el generador web: https://start.ktor.io/ (opens new window) (abrir el archivo zip) o desde el complemento IntellIjIdea (opens new window).
En nuestro caso, como estamos experimentando con numerosos torneos de tenis, vamos a implementar una API REST reactiva para averiguar las raquetas más utilizadas en un torneo de tenis.
Primero debemos crear nuestro proyecto y agregar los siguientes plugins: enrutamiento y serialización de Kotlin. El primero nos permitirá crear las rutas o endpoints para gestionar las raquetas. El segundo nos ofrece la capacidad de intercambiar información en formato JSON.
Es posible que necesitemos otros plugins en el futuro, pero no importa, los agregaremos manualmente más adelante.
En "Ajustar configuración del proyecto", seleccionamos "configuración en archivo HOCON".

# Analizando el código inicial
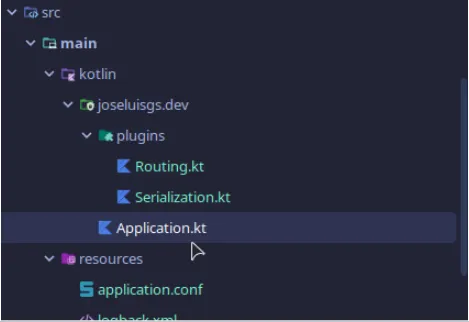
Tenemos la siguiente estructura:
Application: Contiene el código que inicia nuestro servicio y donde se indican los plugins a configurar. plugins/Routing: Define el enrutamiento de nuestra aplicación basado en... plugins/Serialization: Configura la serialización de nuestra aplicación basada en JSON. resources/application.conf: Configura la aplicación en función de las variables de entorno.
# Configurar un Plugin
Puedes configurar un plugin utilizando funciones de extensión. Por ejemplo, "configureRouting" en Application.kt es una función de extensión que define el enrutamiento. Esta función se declara en un paquete de plugin separado (el archivo Routing.kt).
fun Application.configureRouting() {
routing {
get("/") {
call.respondText("¡Hola Mundo!")
}
}
}
2
3
4
5
6
7
# Ejecutar el Servicio
Puedes ejecutar el método principal y luego verificar tu API en http://0.0.0.0:8080. Verás el famoso mensaje: "¡Hola Mundo!"
# Codificando nuestro servicio
# Configurar nuestro servicio
El primer paso es configurar nuestro servicio y agregar algunos puntos adicionales a nuestro archivo application.conf para optimizar el desarrollo. Esta es la primera versión y ampliaremos este archivo en tutoriales posteriores.
# Definir nuestro modelo
El primer paso es definir nuestro modelo. En este caso, es la raqueta (Racket). Lo haremos dentro de una carpeta/paquete llamada "racket". Tendrá un id, marca, modelo, precio, número de jugadores de tenis que la utilizan, una imagen, y la fecha y hora de creación y última modificación. Además, usaremos una constante de id para identificar las raquetas nuevas o existentes.
data class Racket(
val id: Long = NEW_RACKET,
val brand: String,
val model: String,
val price: Double,
val numberTenisPlayers: Int = 0,
val image: String = DEFAULT_IMAGE,
val createdAt: LocalDateTime = LocalDateTime.now(),
val updatedAt: LocalDateTime = LocalDateTime.now(),
val isDeleted: Boolean = false
) {
companion object {
val NEW_RACKET = -1L
const val DEFAULT_IMAGE = "https://i.imgur.com/AsZ2xYS.jpg"
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Desarrollando nuestro repositorio
El patrón de repositorio es un patrón de diseño que aísla la capa de datos del resto de la aplicación. El patrón de repositorio tiene dos propósitos: primero, es una abstracción de la capa de datos, y segundo, es una forma de centralizar el manejo de los objetos del dominio. La idea es tener una forma abstracta y genérica para que la aplicación pueda trabajar con la capa de datos sin importar si la implementación se dirige a una base de datos local, un archivo o una colección en memoria.
Los métodos se basan en las operaciones CRUD: Crear (Create), Leer (Read), Actualizar (Update) y Eliminar (Delete). En la primera versión, utilizamos un mapa como repositorio en memoria (en partes futuras utilizaremos una base de datos reactiva). Usamos funciones suspendidas (suspended functions), flows y tipos nulos (nullable types) para realizar el uso reactivo y asíncrono del repositorio. Utilizaremos interfaces para poder realizar la inyección de dependencias más adelante y cumplir con los principios SOLID. También utilizamos Kotlin Logging (opens new window) para mostrar los mensajes. Además, utilizamos un nuevo contexto y despachador (dispatcher) (opens new window) para ejecutar los métodos en un hilo (thread) especial y no suspender el hilo de la solicitud (request petition).
class RacketsRepositoryImpl : RacketsRepository {
private val rackets = racketsDemoData()
override suspend fun findAll(): Flow<Racket> = withContext(Dispatchers.IO) {
logger.debug { "findAll" }
return@withContext rackets.values.toList().asFlow()
}
override suspend fun findById(id: Long): Racket? = withContext(Dispatchers.IO) {
logger.debug { "findById: $id" }
return@withContext rackets[id]
}
override suspend fun findAllPageable(page: Int, perPage: Int): Flow<Racket> = withContext(Dispatchers.IO) {
logger.debug { "findAllPageable: $page, $perPage" }
val myLimit = if (perPage > 100) 100L else perPage.toLong()
val myOffset = (page * perPage).toLong()
return@withContext rackets.values.toList().subList(myOffset.toInt(), myLimit.toInt()).asFlow()
}
override suspend fun findByBrand(brand: String): Flow<Racket> = withContext(Dispatchers.IO) {
logger.debug { "findByBrand: $brand" }
return@withContext rackets.values
.filter { it.brand.contains(brand, true) }
.asFlow()
}
override suspend fun save(entity: Racket): Racket = withContext(Dispatchers.IO) {
logger.debug { "save: $entity" }
if (entity.id == Racket.NEW_RACQUET) {
create(entity)
} else {
update(entity)
}
}
private fun update(entity: Racket): Racket {
logger.debug { "update: $entity" }
rackets[entity.id] = entity.copy(updatedAt = LocalDateTime.now())
return entity
}
private fun create(entity: Racket): Racket {
logger.debug { "create: $entity" }
val id = rackets.keys.maxOrNull()?.plus(1) ?: 1
val newEntity = entity.copy(id = id, createdAt = LocalDateTime.now(), updatedAt = LocalDateTime.now())
rackets[id] = newEntity
return newEntity
}
override suspend fun delete(entity: Racket): Racket? {
logger.debug { "delete: $entity" }
return rackets.remove(entity.id)
}
override suspend fun deleteAll() {
logger.debug { "deleteAll" }
rackets.clear()
}
override suspend fun saveAll(entities: Iterable<Racket>): Flow<Racket> {
logger.debug { "saveAll: $entities" }
entities.forEach { save(it) }
return entities.asFlow()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
# Configurando nuestras rutas y endpoints
El siguiente paso es definir nuestras rutas para nuestros endpoints; para ello, debemos conocer perfectamente los verbos HTTP (opens new window), los códigos de estado y respuesta (opens new window) y las solicitudes (Requests) (opens new window) y respuestas (Responses) (opens new window) utilizando el DSL de Ktor. Podemos utilizar la siguiente tabla como referencia:
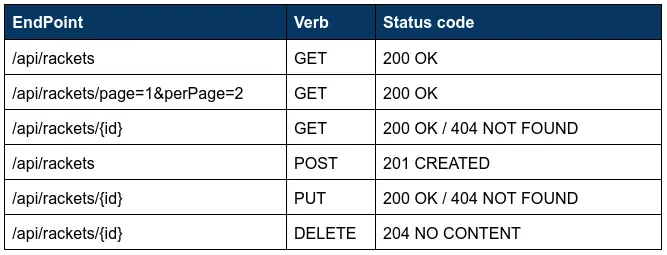
Utilizamos una función de extensión llamada "racketsRoutes()" para definirlo y luego usamos esta función en nuestro plugin de enrutamiento (Routing).
fun Application.configureRouting() {
routing {
get("/") {
call.respondText("Hello World!")
}
}
// Add our routes
racketsRoutes()
}
2
3
4
5
6
7
8
9
10
Recuerda, esta no es la versión final y todavía tenemos que mejorar muchas cosas, pero es un buen punto de partida para verificar nuestro servicio y cómo funciona Ktor. De hecho aún no está programado decentemente, pero es un buen punto de partida para verificar nuestro servicio y cómo funciona Ktor.
// Define endpoint
private const val ENDPOINT = "api/rackets"
fun Application.racketsRoutes() {
// Repository
val rackets: RacketsRepository = RacketsRepositoryImpl()
// Define routing based on endpoint
routing {
route("/$ENDPOINT") {
// Get all rackets --> GET /api/racquets
get {
logger.info { "Get all rackets" }
// QueryParams ??
val page = call.request.queryParameters["page"]?.toIntOrNull()
val perPage = call.request.queryParameters["perPage"]?.toIntOrNull() ?: 10
if (page != null && page > 0) {
logger.debug { "GET ALL /$ENDPOINT?page=$page&perPage=$perPage" }
rackets.findAllPageable(page - 1, perPage).toList()
.run { call.respond(HttpStatusCode.OK, this) }
} else {
logger.debug { "GET ALL /$ENDPOINT" }
rackets.findAll().toList()
.run { call.respond(HttpStatusCode.OK, this) }
}
}
// Get one racket by id --> GET /api/rackets/{id}
get("{id}") {
logger.debug { "GET BY ID /$ENDPOINT/{id}" }
val id = call.parameters["id"]?.toLongOrNull()
id?.let {
rackets.findById(it)?.run { call.respond(HttpStatusCode.OK, this) }
?: call.respond(HttpStatusCode.NotFound, "Racket not found with ID $id")
} ?: call.respond(HttpStatusCode.BadRequest, "ID is not a number")
}
// Get one rackets by brand --> GET /api/rackets/brand/{brand}
get("brand/{brand}") {
logger.debug { "GET BY BRAND /$ENDPOINT/brand/{brand}" }
val brand = call.parameters["brand"]
brand?.let {
rackets.findByBrand(it).toList()
.run { call.respond(HttpStatusCode.OK, this) }
} ?: call.respond(HttpStatusCode.BadRequest, "Brand is not a string")
}
// Create a new racket --> POST /api/rackets
post {
logger.debug { "POST /$ENDPOINT" }
val racket = call.receive<Racket>()
rackets.save(racket)
.run { call.respond(HttpStatusCode.Created, this) }
}
// Update a racket by id --> PUT /api/rackets/{id}
put("{id}") {
logger.debug { "PUT /$ENDPOINT/{id}" }
val id = call.parameters["id"]?.toLongOrNull()
id?.let {
val racket = call.receive<Racket>()
// exists?
rackets.findById(it)?.let {
rackets.save(racket)
.run { call.respond(HttpStatusCode.OK, this) }
} ?: call.respond(HttpStatusCode.NotFound, "Racket not found with ID $id")
} ?: call.respond(HttpStatusCode.BadRequest, "ID is not a number")
}
// Delete a racket by id --> DELETE /api/racquets/{id}
delete("{id}") {
logger.debug { "DELETE /$ENDPOINT/{id}" }
val id = call.parameters["id"]?.toLongOrNull()
id?.let {
// exists?
rackets.findById(it)?.let { racquet ->
rackets.delete(racquet)
.run { call.respond(HttpStatusCode.NoContent) }
} ?: call.respond(HttpStatusCode.NotFound, "Racket not found with ID $id")
} ?: call.respond(HttpStatusCode.BadRequest, "ID is not a number")
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
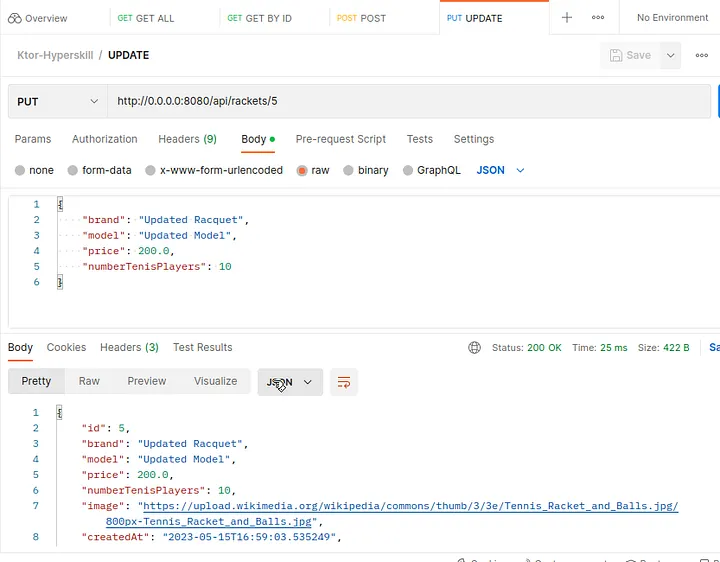
# Probando en Postman
Finalmente, podemos probar nuestra API REST en Postman (opens new window) o cualquier otro cliente REST. Postman es un cliente famoso para probar API REST. Puedes configurar nuestra solicitud y probar las respuestas.
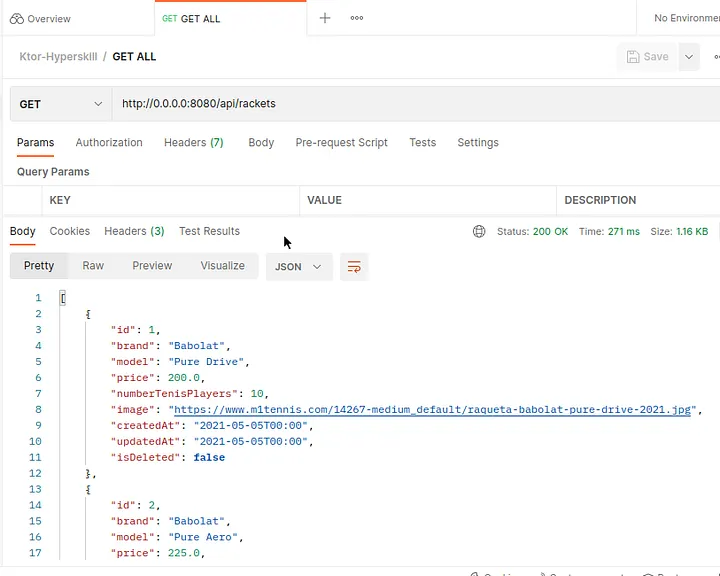
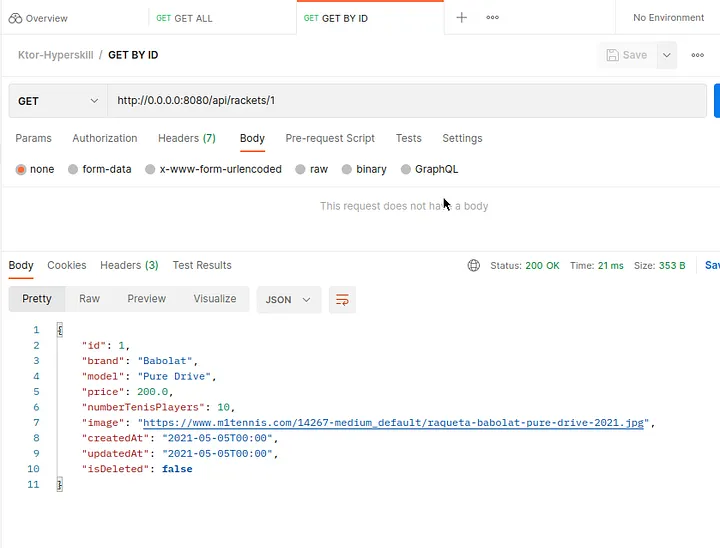
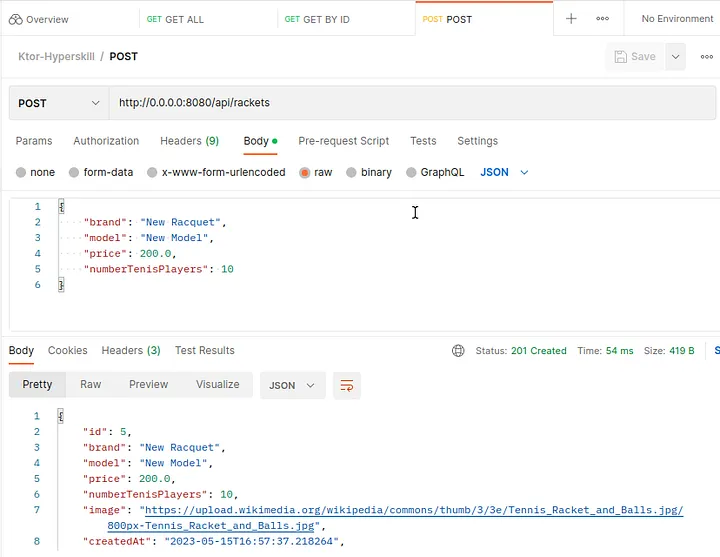

# Conclusión
Hemos comenzado una serie de temas emocionantes para captar las ideas de la programación reactiva y generar una API REST.
Ahora tenemos un buen punto de partida para comenzar a trabajar. Hemos mostrado cómo funciona Ktor para desarrollar una API REST reactiva, pero aún tenemos mucho que mejorar en nuestro código. Pero no todo se puede hacer en el primer paso. Poco a poco iremos aprendiendo lo que necesitamos en los siguientes tutoriales.
Nos hemos centrado en crear nuestros primeros endpoints y probarlos en Postman. Pero todavía tenemos mucho por hacer en futuros tutoriales:
- Validar solicitudes.
- Manejo de errores y excepciones.
- Railway Oriented Programming.
- Uso de un método de caché.
- Uso de una base de datos reactiva.
- Subir archivos.
- Usar websockets para implementar notificaciones en tiempo real.
- Usar Koin para inyectar nuestras dependencias.
- Conexiones seguras con SSL/TSL.
- Autenticación y autorización con JWT.
- Pruebas de nuestros endpoints.
Tienes el código de este proyecto en GitHub (opens new window). El código de esta parte está en Releases (opens new window). Por favor, no olvides darle una estrella o seguirme para estar al tanto de nuevos tutoriales y noticias.
Puedes seguirlo commit por commit y utilizar el archivo de respaldo de Postman para probarlo.
Además, en Hyperskill (opens new window), puedes profundizar y aprender todos los conceptos y más a través de diferentes temas y tareas que te ayudarán a mejorar como desarrollador en tecnologías Kotlin.
Las siguientes trayectorias ofrecidas por JetBrains Academy en Hyperskill pueden ser un punto de partida perfecto. Encontrarás toda la información y explicación de los conceptos y técnicas mostradas en estos artículos. ¡No te los pierdas!
Con estas trayectorias, adquirirás experiencia práctica trabajando con herramientas modernas y aprenderás cómo desarrollar aplicaciones del lado del servidor, mantener los datos persistentes en tus bases de datos y probar la funcionalidad de tus aplicaciones utilizando herramientas modernas.
Déjanos saber en los comentarios si tienes alguna pregunta o comentario sobre este blog. También puedes seguirnos en las redes sociales para estar al tanto de nuestros últimos artículos y proyectos. Estamos en Reddit (opens new window), Twitter (opens new window), LinkedIn (opens new window) y Facebook (opens new window).