Crea tu API REST reactiva con Kotlin y Ktor Parte II

Continuamos con nuestro tutorial de cómo crear una API REST Reactiva y cómo asentar las bases de este paradigma en el desarrollo de servicios como ya vimos en la primera parte. Te recuerdo que esta serie de artículos forman parte de mis actividades con Hyperskill (opens new window) de Jetbrains Academy (opens new window). Se basan en la traducción de lo publicado Medium. Recomiendo que leáis el original en inglés y votéis para que sigan saliendo más partes: Creating Your Reactive REST API with Kotlin and Ktor Part II (opens new window).
Sobre la traducción
Lamentablemente no tengo tiempo para traducir todos los artículos que escribo, para continuar con la primera parte he usado ChatGPT y pulido los errores que me he encontrado. De nuevo te recomiendo la lectura del original en inglés si buscas el 100% de exactitud: Creating Your Reactive REST API with Kotlin and Ktor Part II (opens new window).
# Introducción
Estos tutoriales tienen como objetivo mostrarte todo lo que aprenderás a través de los tracks de Hyperskill (opens new window) de Jetbrains Academy (opens new window). Hyperskill es el lugar perfecto para profundizar, ampliar tus conocimientos y aprender más sobre lo que se presenta en este tutorial. Es la plataforma ideal para aprender tecnologías de Kotlin y utilizar Ktor. Siéntete libre de unirte y continuar tu viaje de aprendizaje. Recuerda que este código es pedagógico y muestra muchos de los contenidos que aprenderás en Hyperskill de manera didáctica y fácil de leer. No tiene la intención de crear el mejor código de producción en entornos reales. Sabemos que muchas cosas se pueden hacer mejor, pero se exageran en el código para que, como estudiante, puedas analizar las posibilidades.
Esta parte es un poco larga porque creamos toda la estructura de características increíbles de nuestro servicio. Tómalo con calma y visita Hyperskill para obtener más funciones geniales para tus servicios de Kotlin y Ktor. No dudes en experimentar y modificar lo que pueda mejorar tu auto-codificación con diferentes ejemplos y alcanzar tus objetivos.
# DTOs y Mappers
Nuestro primer punto es mejorar las solicitudes y respuestas. Para lograr esto, introduciremos un patrón interesante: DTO (opens new window) (Objeto de Transferencia de Datos). DTO (Data Transfer Object) es un patrón de diseño utilizado para transferir datos entre diferentes componentes o capas de una aplicación. Encapsula datos, proporcionando una estructura estandarizada para la comunicación y desacoplando estos datos de los modelos de datos subyacentes. Los DTOs optimizan el rendimiento al reducir la cantidad de datos transferidos y permiten un control detallado sobre la información intercambiada. Mejoran la organización y mantenibilidad del código, y facilitan la evolución de las estructuras de datos.
Gracias a los DTOs, podemos encapsular las solicitudes y respuestas mapeando entidades o diferentes tipos de datos entre ellos. Por ejemplo, imagina que tienes un formato de fecha específico (bastante común), pero lo almacenas en un formato diferente. Con los DTOs, puedes solicitar la fecha como una cadena y almacenarla en el formato adecuado. Además, puedes validar los datos para garantizar su corrección antes de procesarlos. Es posible que no necesitemos todos los datos de nuestra entidad "Racket" (o POKO, Plain Old Kotlin Object) para crear o actualizarla.
Además, tampoco necesariamente tenemos que enviar todos los datos. Cada solicitud y respuesta puede requerir información específica. Aquí es donde los DTOs nos brindan más libertad en el proceso. Aunque no es obligatorio, dependiendo del problema, se recomienda usar DTOs para lograr una mejor flexibilidad y control sobre el proceso de intercambio de datos. Utilizamos DTO como objetos serializables con Kotlin en lugar de nuestra entidad POKO.
@Serializable
data class RacketRequest(
val brand: String,
val model: String,
val price: Double,
val numberTenisPlayers: Int = 0,
val image: String = DEFAULT_IMAGE,
)
@Serializable
data class RacketResponse(
val id: Long,
val brand: String,
val model: String,
val price: Double,
val numberTenisPlayers: Int,
val image: String,
@Serializable(with = LocalDateTimeSerializer::class)
val createdAt: LocalDateTime,
val updatedAt: String,
val isDeleted: Boolean = false
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Si tenemos una clase POKO y varias clases DTO, el siguiente paso es utilizar un mapeador entre ellos. Utilizaremos funciones de extensión que mapean desde RacketRequest a Racket y desde Racket a RacketResponse en un archivo RacketMapper en el paquete Mappers.
fun RacketRequest.toModel() = Racket(
brand = this.brand,
model = this.model,
price = this.price,
numberTenisPlayers = this.numberTenisPlayers,
image = this.image
)
fun Racket.toResponse() = RacketResponse(
id = this.id,
brand = this.brand,
model = this.model,
price = this.price,
numberTenisPlayers = this.numberTenisPlayers,
image = this.image,
createdAt = this.createdAt,
updatedAt = this.updatedAt.toString(),
isDeleted = this.isDeleted
)
fun List<Racket>.toResponse() = this.map { it.toResponse() }
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
En este ejemplo, estamos complicando un poco las cosas. Sin embargo, obtenemos flexibilidad para futuras expansiones y la capacidad de adaptar las solicitudes y respuestas a nuestras necesidades. Puedes aprender todos estos detalles en nuestras pistas de Hyperskill.
# Validaciones y Páginas de Estado
Uno de nuestros problemas fundamentales es asegurarnos de que la información recibida sea correcta en el dominio del problema o de acuerdo con los requisitos de información. Por ejemplo, no tiene sentido que nuestra raqueta tenga un precio negativo o que tengamos una marca o modelo vacío. Podríamos llenar nuestro código con condicionales para asegurar esta tarea y lanzar excepciones, pero Ktor tiene varios complementos para ayudarnos en esta misión.
Para asegurar la corrección de la información entrante, podemos utilizar el complemento RequestValidation (opens new window) en Ktor. Este complemento nos permite validar el cuerpo de las solicitudes entrantes. Ya sea que estemos validando un cuerpo de solicitud sin procesar o propiedades específicas de un objeto de solicitud, el complemento RequestValidation nos cubre. Podemos mejorar aún más nuestras capacidades de validación si también se instala el complemento ContentNegotiation con un serializador. En caso de que falle la validación del cuerpo de la solicitud, el complemento genera una excepción RequestValidationException. Podemos manejar esta excepción utilizando el complemento StatusPages (opens new window), lo que nos permite manejar los errores de validación de manera elegante en nuestra aplicación.
Agregamos las siguientes dependencias en nuestro archivo build.gradle.kts y sincronizamos el proyecto.
// Content Validation
implementation("io.ktor:ktor-server-request-validation:$ktor_version")
// Server Status Pages
implementation("io.ktor:ktor-server-status-pages:$ktor_version")
2
3
4
Ahora configuramos los complementos; en el archivo principal de la aplicación, agregamos dos líneas nuevas:
fun Application.module() {
configureSerialization() // Configure the serialization plugin
configureRouting() // Configure the routing plugin
configureValidation() // Configure the validation plugin
configureStatusPages() // Configure the status pages plugin
}
2
3
4
5
6
En nuestro paquete de plugins, agregamos lo siguiente: Validation.kt.
fun Application.configureValidation() {
install(RequestValidation) {
racketValidation()
}
}
2
3
4
5
En nuestro archivo StatusPages.kt:
fun Application.configureStatusPages() {
install(StatusPages) {
exception<RequestValidationException> { call, cause ->
call.respond(HttpStatusCode.BadRequest, cause.reasons.joinToString())
}
}
}
2
3
4
5
6
7
Con el primer complemento, establecemos todas las reglas de validación. En el segundo, definimos cómo responderemos de forma predeterminada para cada excepción que ocurra en Ktor. Para evitar programar todas las reglas de validación en el mismo archivo, crearemos un paquete llamado "Validations" y colocaremos cada validación de entidad en él. De manera similar, podemos hacer lo mismo con las páginas de estado.
Presentemos las reglas de validación para la entidad Racket. Si la validación falla, lanzará una RequestValidationException y la respuesta devolverá un código de estado de Solicitud Incorrecta (400), gracias a las páginas de estado.
fun RequestValidationConfig.racketValidation() {
validate<RacketRequest> { racket ->
if (racket.brand.isBlank() || racket.brand.length < 3) {
ValidationResult.Invalid("Brand must be at least 3 characters long")
} else if (racket.model.isBlank()) {
ValidationResult.Invalid("Model must not be empty")
} else if (racket.price < 0.0) {
ValidationResult.Invalid("Price must be positive value or zero")
} else if (racket.numberTenisPlayers < 0) {
ValidationResult.Invalid("Number of tennis players must be positive number or zero")
} else {
// Everything is ok!
ValidationResult.Valid
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Ahora podemos mostrar un ejemplo utilizando Postman para probarlo. Ahora podemos ver que una vez que el DTO de solicitud llega a nuestra ruta (endpoint) en una solicitud POST o PUT, el middleware de validación actuará automáticamente. Si alguna de las restricciones especificadas no se cumple, recibiremos una RequestValidationException. Esta excepción será manejada por el sistema de páginas de estado, que recuperará el mensaje de excepción y el código de error indicado.
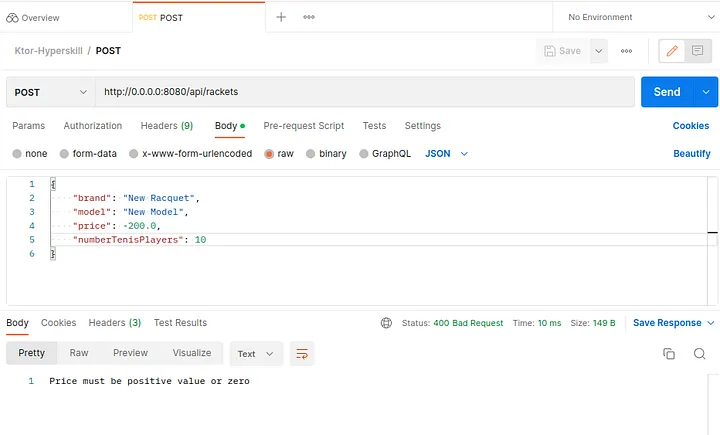
También podemos utilizar esta idea para generar una respuesta de Bad Request cuando el parámetro "id" (para buscar, actualizar o eliminar) no es un número válido.
// When we try to convert a string to a number and it fails we respond with a 400 Bad Request
exception<NumberFormatException> { call, cause ->
call.respond(HttpStatusCode.BadRequest, "${cause.message}. The input param is not a valid number")
}
2
3
4
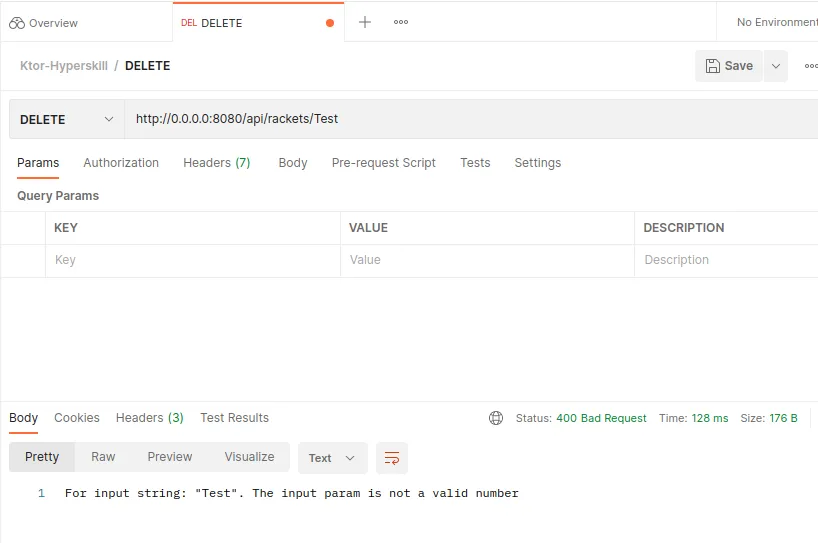
Y aplicarlo en nuestra ruta. Si se produce una NumberFormatException, será gestionada y la página de estado (Status Page) hará su magia.
call.parameters["id"]?.toLong()?.let { id ->
racketsService.findById(id)
}
2
3
# Almacenamiento Reactivo en la Base de Datos
Sabemos que tener un almacenamiento en memoria puede resultar tedioso. Implementemos nuestro repositorio para trabajar con una base de datos reactiva. Ahora, esta es una nueva alternativa; ¿qué nos proporciona?
La diferencia principal entre JDBC (Java Database Connectivity) y R2DBC (Reactive Relational Database Connectivity) radica en su enfoque y funcionamiento.
JDBC es una API tradicionalmente utilizada en entornos Java para interactuar de manera síncrona con bases de datos relacionales. Sigue un enfoque de bloqueo, lo que significa que cada operación de la base de datos bloquea el hilo de ejecución hasta que se completa. Esto puede resultar en una escalabilidad limitada, especialmente en aplicaciones que requieren un alto rendimiento y concurrencia.
Por otro lado, R2DBC es una API reactiva diseñada para la interacción asíncrona y reactiva con bases de datos relacionales. Permite operaciones de base de datos sin bloqueo, lo que significa que el hilo principal de ejecución no se bloquea. En su lugar, utiliza notificaciones y devoluciones de llamada para manejar eventos de manera eficiente. Esto permite una mejor escalabilidad y un rendimiento mejorado en aplicaciones que requieren una alta capacidad de respuesta y el manejo de múltiples solicitudes concurrentes.
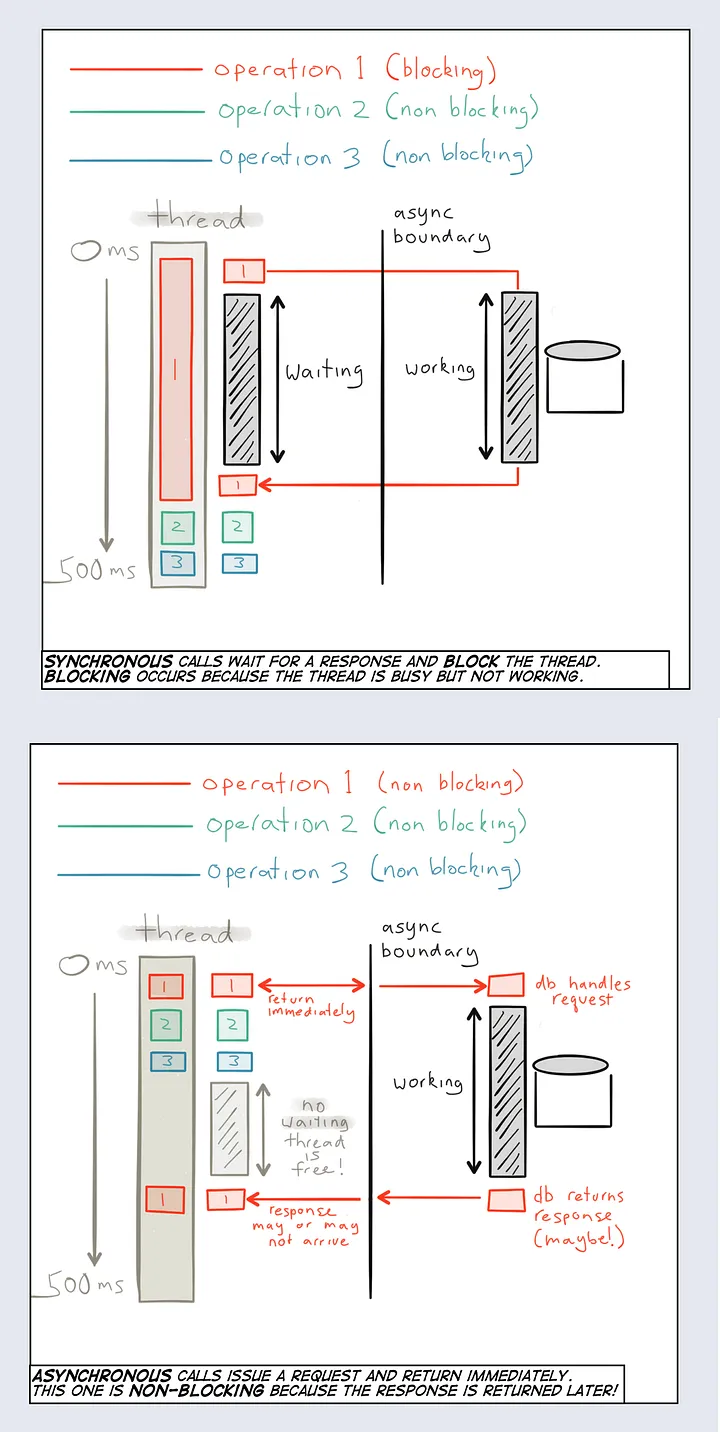
Recuerda, la elección entre JDBC y R2DBC depende de los requisitos específicos de la aplicación y la preferencia por un enfoque síncrono o reactivo. JDBC es una API síncrona que bloquea los hilos de ejecución, mientras que R2DBC es una API reactiva que permite operaciones sin bloqueo y un manejo más eficiente de las solicitudes concurrentes. Sin embargo, esto es una API totalmente reactiva, por lo que seleccionamos un enfoque de base de datos reactivo. Podemos aprender más sobre esta pregunta o alternativa específica en las pistas de Hyperskill.
El primer paso es seleccionar una biblioteca que nos ayude a programar con una base de datos reactiva. Utilizaremos Kotysa (opens new window). Kotysa es un ORM ligero que ofrece una forma idiomática de escribir SQL seguro en términos de tipos de Kotlin utilizando el enfoque JDBC o R2DBC. En modo reactivo, proporciona una API de cliente SQL utilizando funciones suspendidas y Flow de kotlinx.coroutines. Lo utilizaremos como base de datos relacional. Utilizaremos H2 porque podemos utilizarlo como una base de datos en memoria para este proceso de desarrollo.
Una vez más, agregamos las siguientes dependencias en nuestro archivo build.gradle.kts y sincronizamos el proyecto.
implementation("org.ufoss.kotysa:kotysa-r2dbc:$kotysa_version")
implementation("io.r2dbc:r2dbc-h2:$h2_r2dbc_version")
2
# Configuración de la aplicación
Nuestro primer paso es configurar nuestra aplicación para el uso de la base de datos. Para ello, agregaremos opciones a nuestro archivo application.conf para conectarnos a nuestra base de datos, como la URL de conexión, nombre de usuario y contraseña. Incluiremos una clave especial para inicializar los datos en modo de desarrollo.
database {
driver = "h2"
protocol ="mem"
user = "sa"
user = ${?DATABASE_USER}
password = ""
password = ${?DATABASE_PASSWORD}
database = "r2dbc:h2:mem:///rackets;DB_CLOSE_DELAY=-1"
database = ${?DATABASE_NAME}
## Init database data
initDatabaseData = true
}
2
3
4
5
6
7
8
9
10
11
12
# Definiendo Tablas y Entidades
El siguiente paso es definir la estructura de nuestras tablas y la entidad de fila para mapear los datos. Podemos utilizar nuestro modelo de Racket original POKO. Nuevamente, esto es opcional pero recomendado. Al igual que con los DTOs, esto nos permite mapear los datos entre nuestro modelo POKO y nuestra entidad en caso de incompatibilidades de datos. Hemos elegido este enfoque porque no queremos valores nulos en el campo de ID, pero Kotysa los requiere para determinar si debe generar una clave de autoincremento. Este comportamiento podría cambiar en futuras versiones (opens new window). En un nuevo paquete llamado Entities, codificamos la Tabla Racket y la Entidad Racket.
object RacketTable : H2Table<RacketEntity>() {
// Autoincrement and primary key
val id = autoIncrementBigInt(RacketEntity::id).primaryKey()
// Other fields
val brand = varchar(RacketEntity::brand)
val model = varchar(RacketEntity::model)
val price = doublePrecision(RacketEntity::price)
val numberTenisPlayers = integer(RacketEntity::numberTenisPlayers, "number_tenis_players")
val image = varchar(RacketEntity::image, "image")
// metadata
val createdAt = timestamp(RacketEntity::createdAt, "created_at")
val updatedAt = timestamp(RacketEntity::updatedAt, "updated_at")
val isDeleted = boolean(RacketEntity::isDeleted, "is_deleted")
}
data class RacketEntity(
val id: Long?,
val brand: String,
val model: String,
val price: Double,
val numberTenisPlayers: Int = 0,
val image: String = DEFAULT_IMAGE,
val createdAt: LocalDateTime = LocalDateTime.now(),
val updatedAt: LocalDateTime = LocalDateTime.now(),
val isDeleted: Boolean = false
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Y agregamos los siguientes métodos a nuestro Racket Mapper.
fun RacketEntity.toModel() = Racket(
id = this.id ?: Racket.NEW_RACKET,
brand = this.brand,
model = this.model,
price = this.price,
numberTenisPlayers = this.numberTenisPlayers,
image = this.image,
createdAt = this.createdAt,
updatedAt = this.updatedAt,
isDeleted = this.isDeleted
)
fun List<RacketEntity>.toModel() = this.map { it.toModel() }
fun Racket.toEntity() = RacketEntity(
id = if (this.id == Racket.NEW_RACKET) null else this.id,
brand = this.brand,
model = this.model,
price = this.price,
numberTenisPlayers = this.numberTenisPlayers,
image = this.image,
createdAt = this.createdAt,
updatedAt = this.updatedAt,
isDeleted = this.isDeleted
)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# Codificando el Cliente del Servicio de Base de Datos
En esta versión inicial, crearemos un Cliente de Servicio de Base de Datos que se encargará de crear dicho cliente, crear las tablas e iniciar los datos. Puedes encontrarlo en el paquete: Services -> Database. Este cliente cargará la configuración y los parámetros de la base de datos desde nuestro archivo application.conf, los cuales inyectaremos en el constructor.
class DataBaseService(
private val dataBaseConfig: ApplicationConfig = ApplicationConfig("application.conf")
) {
private val connectionFactory by lazy {
val options = ConnectionFactoryOptions.builder()
.option(ConnectionFactoryOptions.DRIVER, dataBaseConfig.property("database.driver").getString())
.option(ConnectionFactoryOptions.PROTOCOL, dataBaseConfig.property("database.protocol").getString())
.option(ConnectionFactoryOptions.USER, dataBaseConfig.property("database.user").getString())
.option(ConnectionFactoryOptions.PASSWORD, dataBaseConfig.property("database.password").getString())
.option(ConnectionFactoryOptions.DATABASE, dataBaseConfig.property("database.database").getString())
.build()
ConnectionFactories.get(options)
}
private val initDatabaseData by lazy {
dataBaseConfig.propertyOrNull("database.initDatabaseData")?.getString()?.toBoolean() ?: false
}
// Our client
val client = connectionFactory.coSqlClient(getTables())
init {
logger.debug { "Init DataBaseService" }
initDatabase()
}
// Our tables
private fun getTables(): H2Tables {
// Return tables
return tables().h2(RacketTable)
}
fun initDatabase() = runBlocking {
logger.debug { "Init DatabaseService" }
createTables()
// Init data
if (initDatabaseData) {
initDataBaseDataDemo()
}
}
// demo data
suspend fun initDataBaseDataDemo() {
clearDataBaseData()
initDataBaseData()
}
// Create tables if not exists
private suspend fun createTables() = withContext(Dispatchers.IO) {
logger.debug { "Creating the tables..." }
launch {
client createTableIfNotExists RacketTable
}
}
// Clear all data
private suspend fun clearDataBaseData() = withContext(Dispatchers.IO) {
logger.debug { "Deleting data..." }
launch {
client deleteAllFrom RacketTable
}
}
// Init data
private suspend fun initDataBaseData() = withContext(Dispatchers.IO) {
logger.debug { "Saving rackets demo data..." }
launch {
racketsDemoData().forEach {
client insert it.value.copy(id = Racket.NEW_RACKET).toEntity()
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
# Actualizando el repositorio para usar nuestro sistema de almacenamiento en la base de datos
Por último, actualizamos nuestro repositorio de rackets para utilizar el sistema de almacenamiento en la base de datos. Inyectamos nuestra dependencia de la base de datos en el constructor.
class RacketsRepositoryImpl(
private val dataBaseService: DataBaseService
) : RacketsRepository {
override suspend fun findAll(): Flow<Racket> = withContext(Dispatchers.IO) {
logger.debug { "findAll" }
return@withContext (dataBaseService.client selectFrom RacketTable)
.fetchAll().map { it.toModel() }
}
override suspend fun findById(id: Long): Racket? = withContext(Dispatchers.IO) {
logger.debug { "findById: $id" }
return@withContext (dataBaseService.client selectFrom RacketTable
where RacketTable.id eq id)
.fetchFirstOrNull()?.toModel()
}
override suspend fun findAllPageable(page: Int, perPage: Int): Flow<Racket> = withContext(Dispatchers.IO) {
logger.debug { "findAllPageable: $page, $perPage" }
val myLimit = if (perPage > 100) 100L else perPage.toLong()
val myOffset = (page * perPage).toLong()
return@withContext (dataBaseService.client selectFrom RacketTable
limit myLimit offset myOffset)
.fetchAll().map { it.toModel() }
}
override suspend fun findByBrand(brand: String): Flow<Racket> = withContext(Dispatchers.IO) {
logger.debug { "findByBrand: $brand" }
return@withContext (dataBaseService.client selectFrom RacketTable)
.fetchAll()
.filter { it.brand.contains(brand, true) }
.map { it.toModel() }
}
override suspend fun save(entity: Racket): Racket = withContext(Dispatchers.IO) {
logger.debug { "save: $entity" }
if (entity.id == Racket.NEW_RACKET) {
create(entity)
} else {
update(entity)
}
}
private suspend fun create(entity: Racket): Racket {
val newEntity = entity.copy(createdAt = LocalDateTime.now(), updatedAt = LocalDateTime.now())
.toEntity()
logger.debug { "create: $newEntity" }
return (dataBaseService.client insertAndReturn newEntity).toModel()
}
private suspend fun update(entity: Racket): Racket {
logger.debug { "update: $entity" }
val updateEntity = entity.copy(updatedAt = LocalDateTime.now()).toEntity()
(dataBaseService.client update RacketTable
set RacketTable.brand eq updateEntity.brand
set RacketTable.model eq updateEntity.model
set RacketTable.price eq updateEntity.price
set RacketTable.numberTenisPlayers eq updateEntity.numberTenisPlayers
set RacketTable.image eq updateEntity.image
where RacketTable.id eq entity.id)
.execute()
return updateEntity.toModel()
}
override suspend fun delete(entity: Racket): Racket {
logger.debug { "delete: $entity" }
(dataBaseService.client deleteFrom RacketTable
where RacketTable.id eq entity.id)
.execute()
return entity
}
override suspend fun deleteAll() {
logger.debug { "deleteAll" }
dataBaseService.client deleteAllFrom RacketTable
}
override suspend fun saveAll(entities: Iterable<Racket>): Flow<Racket> {
logger.debug { "saveAll: $entities" }
entities.forEach { save(it) }
return this.findAll()
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
# Codificando nuestros servicios.
El siguiente paso es enriquecer el servicio de API, de modo que encapsule nuestro repositorio como un servicio que incluya diferentes funcionalidades además de guardar la información en una base de datos.
# Caché
El sistema de caché es recomendado para servidores por las siguientes razones:
- Mejora el rendimiento general almacenando datos de acceso frecuente más cerca del procesador, reduciendo la latencia.
- Ayuda a reducir la carga en la memoria principal del servidor, permitiendo un acceso más rápido a los datos críticos.
- La caché minimiza el tráfico de red al servir contenido directamente desde la caché, reduciendo la necesidad de solicitudes de datos repetidas.
- Mejora la escalabilidad al manejar eficientemente un aumento en las solicitudes de los usuarios y optimizar los recursos del servidor.
Utilizamos una caché reactiva, Cache4k (opens new window), para agregarlo a nuestro archivo build.gradle.kts y sincronizar el proyecto.
// Cache 4K for in-memory cache
implementation("io.github.reactivecircus.cache4k:cache4k:$cache_version")
2
Para utilizar nuestro servicio de caché, crearemos un servicio llamado CacheService con los parámetros obtenidos de application.conf. En nuestra implementación de RacketService, utilizaremos el siguiente algoritmo para utilizar nuestra caché: si solicitamos un racket, lo buscamos en la caché y solo si no existe, lo obtenemos de la base de datos (posteriormente lo agregamos a la caché para búsquedas futuras). Si no existe, devolvemos un error. Actualizamos la caché con los nuevos datos si agregamos o modificamos un racket. Y si eliminamos un racket, lo invalidamos en la caché. Aquí tienes un prototipo de findById, pero necesitaremos agregar más cosas 😉.
override suspend fun findById(id: Long): Racket {
logger.debug { "findById: search racket by id" }
// find in cache if not found find in repository
return cacheService.rackets.get(id)?.let {
logger.debug { "findById: found in cache" }
it
} ?: run {
racketsRepository.findById(id)?.let { racket ->
logger.debug { "findById: found in repository" }
cacheService.rackets.put(id, racket)
racket
} ?: throw RuntimeException("Racket not found")
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
# Railway Oriented Programming (ROP)
ROP (opens new window) es un concepto de programación funcional para manejar errores y componer operaciones secuenciales. Organiza las operaciones en una secuencia de pasos, donde cada paso puede tener éxito y continuar al siguiente paso en el camino deseado o fallar y dirigirse a un camino de manejo de errores. Las ventajas de ROP son:
- Manejo de errores mejorado: ROP proporciona un enfoque estructurado para manejar errores, lo que facilita el seguimiento y la predicción de fallas.
- Componibilidad: ROP permite la composición de múltiples operaciones en una secuencia única, lo que facilita el razonamiento y el mantenimiento del código.
- Separación de responsabilidades: ROP fomenta la separación de la lógica de negocio del código de manejo de errores, lo que resulta en un código más limpio y más fácil de mantener. ROP proporciona un enfoque estructurado para manejar errores y permite la ramificación explícita basada en el éxito o el fracaso. En contraste, las excepciones pueden manejar casos excepcionales o errores inesperados.
- Testabilidad: ROP facilita las pruebas unitarias al permitir que cada paso se pruebe individualmente y facilitar el uso de simulaciones o stubs de dependencias.

Para utilizar esta técnica de programación, agregamos las siguientes líneas a nuestro archivo gradle.build.kts y sincronizamos el proyecto para usar la biblioteca kotlin-result (opens new window):
// Result for error handling Railway Oriented Programming
implementation("com.michael-bull.kotlin-result:kotlin-result:$result_version")
2
Creamos la estructura de errores para las operaciones de Racket.
sealed class RacketError(val message: String) {
class NotFound(message: String) : RacketError(message)
class BadRequest(message: String) : RacketError(message)
}
2
3
4
Ahora podemos usarlo en nuestro servicio y ruta. Por ejemplo, tenemos un ejemplo para encontrar una raqueta con nuestro servicio:
override suspend fun findById(id: Long): Result<Racket, RacketError> {
logger.debug { "findById: search racket by id" }
// find in cache if not found find in repository
return cacheService.rackets.get(id)?.let {
logger.debug { "findById: found in cache" }
Ok(it)
} ?: run {
racketsRepository.findById(id)?.let { racket ->
logger.debug { "findById: found in repository" }
cacheService.rackets.put(id, racket)
Ok(racket)
} ?: Err(RacketError.NotFound("Racket with id $id not found"))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
Y como buscar una raqueta por un id en nuestra ruta.
// Get one racket by id --> GET /api/rackets/{id}
get("{id}") {
logger.debug { "GET BY ID /$ENDPOINT/{id}" }
call.parameters["id"]?.toLong()?.let { id ->
racketsService.findById(id).mapBoth(
success = { call.respond(HttpStatusCode.OK, it.toResponse()) },
failure = { handleRacketErrors(it) }
)
}
}
2
3
4
5
6
7
8
9
10
Utilizamos mapBoth para separar el resultado exitoso del error. Podemos manejar todos los errores gracias a una función de extensión handleRacketErrors, donde pasamos el error y, en este punto, realizamos la respuesta correcta para cada tipo de error. Así, nuestro código es mucho más limpio en comparación con la primera versión.
private suspend fun PipelineContext<Unit, ApplicationCall>.handleRacketErrors(
error: RacketError,
) {
// We can handle the errors in a different way
when (error) {
// Racket Errors
is RacketError.NotFound -> call.respond(HttpStatusCode.NotFound, error.message)
is RacketError.BadRequest -> call.respond(HttpStatusCode.BadRequest, error.message)
}
}
2
3
4
5
6
7
8
9
10
# Notificaciones en tiempo real con WebSockets
WebSocket (opens new window) es un protocolo de comunicación que proporciona comunicación full-duplex entre un cliente y un servidor a través de una única conexión duradera. Permite la comunicación bidireccional en tiempo real entre los dos puntos finales. Podemos utilizar WebSocket cuando:
- Se requieren datos en tiempo real: WebSocket es adecuado para aplicaciones que necesitan actualizaciones instantáneas o intercambio frecuente de datos entre el cliente y el servidor.
- Aplicaciones interactivas: Es ideal para aplicaciones que involucran colaboración en tiempo real, sistemas de chat, juegos o cualquier escenario en el que la comunicación instantánea sea vital.
- Latencia reducida: WebSocket elimina la necesidad de realizar consultas continuas o solicitudes frecuentes, lo que reduce la sobrecarga de red y mejora la capacidad de respuesta.
- Utilización eficiente de recursos: Permite conexiones simultáneas y persistentes, reduciendo la sobrecarga de establecer nuevas conexiones para cada interacción y permitiendo una utilización eficiente de los recursos en el servidor.
Por lo tanto, implementamos nuestro sistema de notificaciones cuando agregamos, actualizamos o eliminamos una raqueta. Podemos utilizar el patrón Observer (opens new window) (observador) (consultar los commits del repositorio), pero en este caso, utilizamos un estado reactivo utilizando StateFlow (opens new window) o SharedFlow (opens new window) de Kotlin Coroutines. En la tercera parte del tutorial será un SharedFlow. El patrón Observer es útil para notificaciones en tiempo real a una lista de suscriptores, mientras que StateFlow en Kotlin proporciona un flujo de datos reactivo con notificaciones automáticas de cambios relevantes. El patrón Observer se adapta mejor a listas más pequeñas de suscriptores y cambios poco frecuentes, mientras que StateFlow es ideal para aprovechar las capacidades reactivas de Kotlin y manejar flujos de datos a mayor escala. La elección depende de la complejidad del sistema, el tamaño de la lista de suscriptores, la frecuencia de los cambios y la capacidad de respuesta requerida. Considera tus necesidades específicas al seleccionar el enfoque adecuado. Entonces, creamos un DTO de notificación y en nuestro servicio de raquetas creamos el estado reactivo y una función para modificarlo.
// Real Time Notifications and WebSockets
// We can notify use a reactive system with StateFlow
private val _notificationState: MutableStateFlow<RacketNotification> = MutableStateFlow(
RacketNotification(
entity = "",
type = NotificationType.OTHER,
id = null,
data = null
)
)
override val notificationState: StateFlow<RacketNotification> = _notificationState
private suspend fun onChange(type: NotificationType, id: Long, data: Racket) {
logger.debug { "onChange: Notification on Rackets: $type, notification updates to subscribers: $data" }
// update notification state
_notificationState.value = RacketNotification(
entity = "RACKET",
type = type,
id = id,
data = data.toResponse()
)
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
Por ejemplo, si eliminamos una nueva raqueta en nuestro servicio, podemos actualizar el estado:
override suspend fun delete(id: Long): Result<Racket, RacketError> {
logger.debug { "delete: delete racket" }
// find, if exists delete in cache and repository and notify
return findById(id).andThen {
Ok(racketsRepository.delete(it).also { res ->
cacheService.rackets.invalidate(id)
onChange(NotificationType.DELETE, id, res)
})
}
}
2
3
4
5
6
7
8
9
10
Pero necesitamos interactuar como un servicio web en nuestra ruta. Incluimos la dependencia en nuestro archivo build.gradle.kts y sincronizamos el proyecto.
// WebSockets
implementation("io.ktor:ktor-server-websockets:$ktor_version")
2
Hemos configurado el complemento WebSocket (en el paquete Plugins), y necesitamos agregar la configuración al módulo de la aplicación, al igual que los otros complementos. Creamos una ruta para nuestro WebSocket en nuestra ruta principal y reaccionamos al cambio del estado de notificación consumiendo el StateFlow o SharedFlow.
// WebSockets Real Time Updates and Notifications
webSocket("/$ENDPOINT/notifications") {
sendSerialized("Notifications WS: Rackets - Rackets API")
val initTime = LocalDateTime.now()
// Remember it will autoclose the connection, see config
// Now we can listen and react to the changes in the StateFlow
racketsService.notificationState
// Sometimes we need to do something when we start
.onStart {
logger.debug { "notificationState: onStart to ${this.hashCode()}" }
// Sometimes we need to filter any values
}.filter {
// we filter the values: we only send the ones that are not empty and are after the init time
it.entity.isNotEmpty() && it.createdAt.isAfter(initTime)
// we collect the values and send them to the client
}.collect {
logger.debug { "notificationState: collect $it and sent to ${this.hashCode()}" }
sendSerialized(it) // WS function to send the message to the client
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
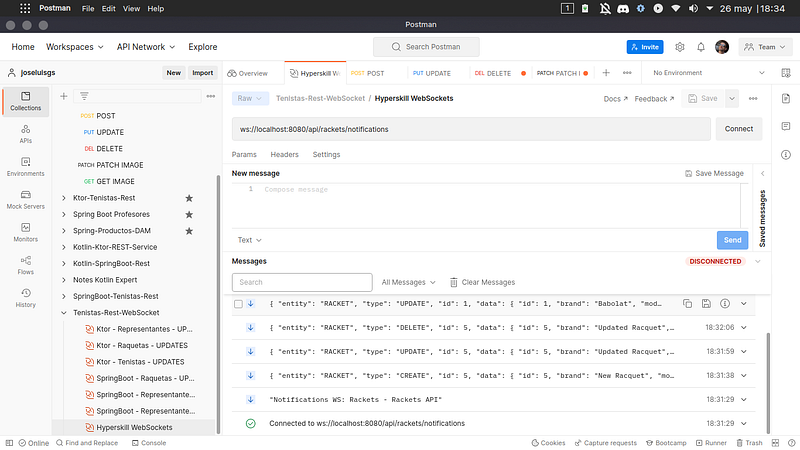
Ahora podemos probarlo en Postman, gracias a la funcionalidad de WebSocket (opens new window):
# Almacenamiento de archivos
La siguiente etapa consiste en crear un servicio de almacenamiento para cargar archivos, como por ejemplo, la imagen de cada raqueta. En el archivo application.conf utilizaremos una clave especial para indicar el directorio de carga donde se guardarán los archivos. Para ello, programaremos en este servicio dos métodos: uno para guardar una imagen y otro para recuperarla. También crearemos una estructura de errores y utilizaremos Result (ROP) para manejar los resultados.
override suspend fun saveFile(
fileName: String,
fileUrl: String,
fileBytes: ByteArray
): Result<Map<String, String>, StorageError> =
withContext(Dispatchers.IO) {
logger.debug { "Saving file in: $fileName" }
return@withContext try {
File("${uploadDir}/$fileName").writeBytes(fileBytes)
Ok(
mapOf(
"fileName" to fileName,
"createdAt" to LocalDateTime.now().toString(),
"size" to fileBytes.size.toString(),
"url" to fileUrl,
)
)
} catch (e: Exception) {
Err(StorageError.BadRequest("Error saving file: $fileName"))
}
}
override suspend fun getFile(fileName: String): Result<File, StorageError> = withContext(Dispatchers.IO) {
logger.debug { "Get file: $fileName" }
return@withContext if (!File("${uploadDir}/$fileName").exists()) {
Err(StorageError.NotFound("File Not Found in storage: $fileName"))
} else {
Ok(File("${uploadDir}/$fileName"))
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Entonces, en nuestra ruta podemos usar una petición de parche para actualizar la imagen de la raqueta usando una solicitud de varias partes (opens new window):
// Update a racket image --> PATCH /api/rackets/{id}
patch("{id}") {
logger.debug { "PATCH /$ENDPOINT/{id}" }
call.parameters["id"]?.toLong()?.let { id ->
val baseUrl =
call.request.origin.scheme + "://" + call.request.host() + ":" + call.request.port() + "/$ENDPOINT/image/"
val multipartData = call.receiveMultipart()
multipartData.forEachPart { part ->
if (part is PartData.FileItem) {
val fileName = part.originalFileName as String
val fileBytes = part.streamProvider().readBytes()
val fileExtension = fileName.substringAfterLast(".")
val newFileName = "${System.currentTimeMillis()}.$fileExtension"
val newFileUrl = "$baseUrl$newFileName"
// Save the file
storageService.saveFile(newFileName, newFileUrl, fileBytes).andThen {
// Update the racket Image
racketsService.updateImage(
id = id,
image = newFileUrl
)
}.mapBoth(
success = { call.respond(HttpStatusCode.OK, it.toResponse()) },
failure = { handleRacketErrors(it) }
)
}
part.dispose()
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
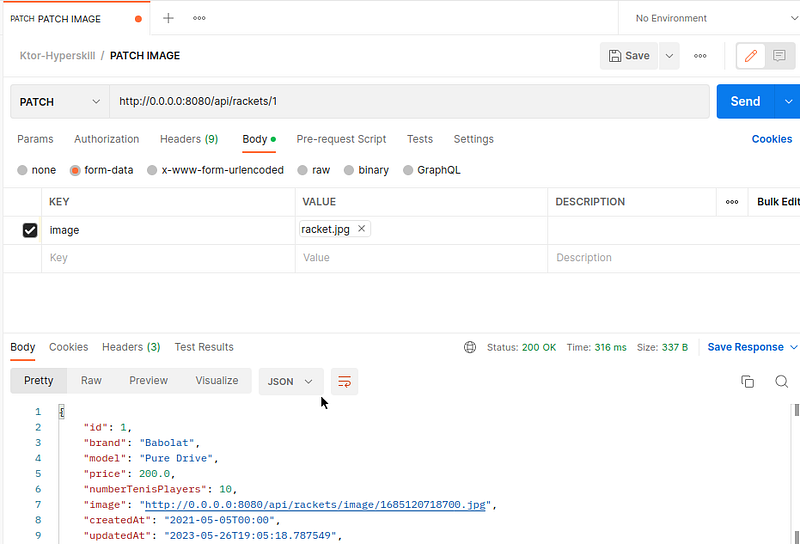
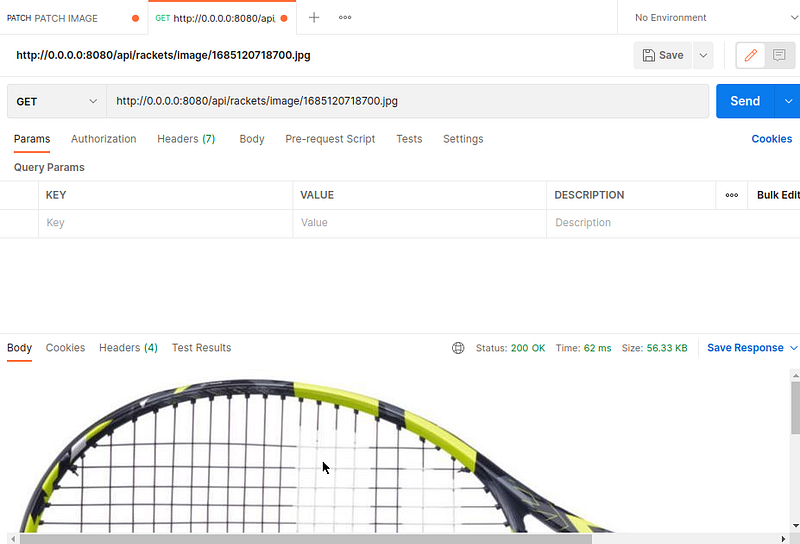
Ahora podemos probar con Postman para enviar un archivo y actualizar una raqueta u obtener este archivo.
# Nuestra Ruta Final
Finalmente, tenemos nuestra ruta que llama a los servicios que utilizaremos. Destacamos el enfoque de ROP y cómo manejamos todos los errores mediante la creación de un código limpio y legible que concatena opciones basadas en el flujo principal o utiliza websockets con un estado reactivo para implementar un sistema de notificación en tiempo real.
# Testing
# Testeando el repositorio de raquetas
Ahora entramos en una parte crucial y esencial: probar nuestro código. Para hacer esto, haremos uso de JUnit (opens new window). JUnit es un ampliamente utilizado marco de pruebas de código abierto para aplicaciones Java. Proporciona una forma simple y conveniente de escribir y ejecutar pruebas unitarias para unidades individuales de código, como métodos o clases. JUnit ofrece varias anotaciones, aserciones y ejecutores de pruebas para facilitar la creación y ejecución de pruebas. Ampliaremos la configuración para usar una biblioteca especial para probar funciones suspendidas. Agregamos las siguientes dependencias en nuestro archivo build.gradle.kts y sincronizamos el proyecto.
// Testing
testImplementation("io.ktor:ktor-server-tests-jvm:$ktor_version")
// testImplementation("org.jetbrains.kotlin:kotlin-test-junit:$kotlin_version")
// JUnit 5 instead of JUnit 4
testImplementation("org.junit.jupiter:junit-jupiter-api:$junit_version")
testImplementation("org.junit.jupiter:junit-jupiter-engine:$junit_version")
// To test coroutines and suspend functions
testImplementation("org.jetbrains.kotlinx:kotlinx-coroutines-test:$coroutines_test_version")
2
3
4
5
6
7
8
En esta etapa inicial, las pruebas no son las mejores para un repositorio, pero son ilustrativas para lo que queremos. Podemos ver el uso de aserciones para verificar las operaciones CRUD indicadas. En la carpeta de pruebas, puedes encontrar los archivos de prueba.
class RacketsRepositoryImplTest {
val dataBaseService = DataBaseService(ApplicationConfig("application.conf"))
val repository = RacketsRepositoryImpl(dataBaseService)
@BeforeEach
fun setUp() = runTest {
// Clean and restore database with data
dataBaseService.initDataBaseDataDemo()
}
@Test
fun findAll() = runTest {
val rackets = repository.findAll().toList()
assertAll(
{ assertEquals(4, rackets.size) },
{ assertEquals("Babolat", rackets[0].brand) },
{ assertEquals("Babolat", rackets[1].brand) },
{ assertEquals("Head", rackets[2].brand) },
{ assertEquals("Wilson", rackets[3].brand) }
)
}
@Test
suspend fun findById() = runTest {
val racket = repository.findById(1)!!
assertAll(
{ assertEquals(1, racket.id) },
{ assertEquals("Babolat", racket.brand) }
)
}
@Test
fun findByIdNotFound() = runTest {
val racket = repository.findById(-100)
assertNull(racket)
}
// . . .
@Test
fun saveNewRacket() = runTest {
val racket = Racket(brand = "Test Brand", model = "Test Model", price = 100.0)
val newRacket = repository.save(racket)
assertAll(
{ assertEquals("Test Brand", newRacket.brand) },
{ assertEquals("Test Model", newRacket.model) },
{ assertEquals(100.0, newRacket.price) }
)
}
// . . .
@Test
fun delete() = runTest {
// Save a new racket
val racket = Racket(brand = "Test Brand", model = "Test Model", price = 100.0)
val newRacket = repository.save(racket)
val deleted = repository.delete(newRacket)
val exists = repository.findById(newRaquet.id)
assertAll(
{ assertEquals("Test Brand", deleted.brand) },
{ assertEquals("Test Model", deleted.model) },
{ assertEquals(100.0, deleted.price) },
{ assertNull(exists) }
)
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
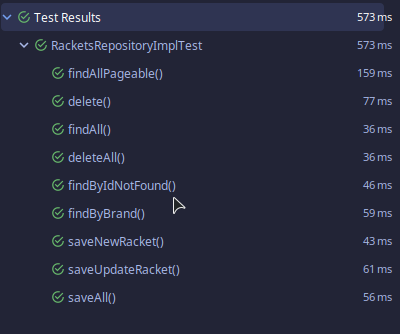
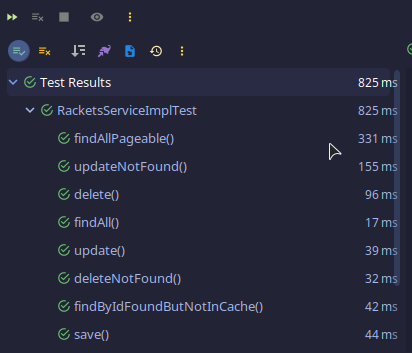
Ejecutando nuestras pruebas obtenemos:
# Testeando el servicio de raquetas
Para probar nuestro servicio, utilizaremos pruebas con "mocks". Las pruebas con "mocks" implican la creación de objetos simulados que imitan el comportamiento de las dependencias reales. Estos objetos simulados están programados para responder a las llamadas a métodos y permiten establecer expectativas sobre sus interacciones. Utilizando "mocks", los desarrolladores pueden aislar el código que se está probando, controlar el comportamiento de las dependencias, simular diversos escenarios y verificar las interacciones con el código probado.
Utilizaremos la biblioteca MockK (opens new window), por lo que debemos agregar la siguiente dependencia a nuestro proyecto en el archivo build.gradle.kts y sincronizar nuestro proyecto:
// MockK para pruebas con "mocks"
testImplementation("io.mockk:mockk:$mockk_version")
2
Crearemos una clase para probar los métodos del servicio. Extendemos la clase con @ExtendWith(MockKExtension::class) para realizar las pruebas con JUnit y creamos los "mocks" con las anotaciones @MockK e @InjectMockK para inyectar el "mock" como dependencia de la clase que se está probando.
A continuación, creamos cada prueba donde simulamos el comportamiento del "mock" para responder a las llamadas a métodos y permitir expectativas para probar los métodos del servicio con JUnit. Podemos verificar el número de llamadas a una dependencia.
@ExtendWith(MockKExtension::class)
class RacketsServiceImplTest {
@MockK
lateinit var repository: RacketsRepositoryImpl
@MockK
lateinit var cache: CacheService
@InjectMockKs
lateinit var service: RacketsServiceImpl
val rackets = racketsDemoData().values
@Test
fun findAll() = runTest {
// Given
coEvery { repository.findAll() } returns flowOf(rackets.first())
// When
val result = service.findAll().toList()
// Then
assertAll(
{ assertNotNull(result) },
{ assertEquals(1, result.size) },
{ assertEquals(rackets.first(), result.first()) }
)
// Verifications
coVerify(exactly = 1) { repository.findAll() }
}
// ...
@Test
fun save() = runTest {
// Given
coEvery { repository.save(any()) } returns rackets.first()
coEvery { cache.rackets.put(any(), rackets.first()) } just runs // returns Unit
// When
val result = service.save(rackets.first())
// Then
assertAll(
{ assertNotNull(result) },
{ assertEquals(rackets.first(), result.get()) }
)
// Verifications
coVerify { repository.save(any()) }
coVerify { cache.rackets.put(any(), rackets.first()) }
}
// ...
@Test
fun delete() = runTest {
// Given
coEvery { cache.rackets.get(any()) } returns null
coEvery { repository.findById(any()) } returns rackets.first()
coEvery { cache.rackets.put(any(), rackets.first()) } just runs
coEvery { repository.delete(any()) } returns rackets.first()
coEvery { cache.rackets.invalidate(any()) } returns Unit
// When
val result = service.delete(1)
// Then
assertAll(
{ assertNotNull(result) },
{ assertEquals(rackets.first(), result.get()) }
)
// Verifications
coVerify { cache.rackets.get(any()) }
coVerify { repository.findById(any()) }
coVerify { cache.rackets.put(any(), rackets.first()) }
coVerify { repository.delete(any()) }
coVerify { cache.rackets.invalidate(any()) }
}
// ...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
De nuevo ejecutando nuestros tests:
# ¿Qué sigue?
Puedes probar con Postman y, por qué no, probar nuestro proceso de validación. Puedes seguir los mensajes o el registro para entender la secuencia o los métodos.
Hemos continuado nuestros tutoriales para poder programar nuestra API REST reactiva, comprendiendo gradualmente cada uno de sus componentes. Pero aún nos queda mucho por hacer en el tutorial final. Por favor, no dejes de seguir el resto de las publicaciones de Hyperskill en Medium, donde veremos más detalles de lo que puedes aprender en nuestras pistas. Codificaremos este ejemplo:
- Usar Koin para inyectar nuestras dependencias.
- Conexiones seguras con SSL.
- Autenticación y autorización con JWT.
- Prueba de nuestros puntos finales (endpoints).
- Documentación de nuestro servicio con Swagger y OpenAPI.
- Despliegue con Docker.
Tienes el código de este proyecto en https://github.com/joseluisgs/ktor-reactive-rest-hyperskill. El código de esta parte está en este enlace: https://github.com/joseluisgs/ktor-reactive-rest-hyperskill/releases. Por favor, no olvides dar una estrella o seguirme para estar al tanto de nuevos tutoriales y noticias.
Puedes seguirlo commit por commit y usar el archivo de respaldo de Postman para probarlo.
Recuerda que este no es un código para usar en un entorno real o de producción. Es un proyecto didáctico para que puedas experimentar, analizar, mejorar o adaptar a tu forma de programar. Se trata de presentar conceptos y ver cómo funcionan. Cualquier sugerencia o propuesta que tengas, puedes hacer un "issue" o una solicitud de extracción (pull request).
Sin embargo, todavía tenemos muchas secciones por cubrir y contenido para que profundices y refuerces en Hyperskill (opens new window) a través de diferentes temas y tareas que te ayudarán a mejorar como desarrollador en tecnologías Kotlin. Las siguientes pistas ofrecidas por JetBrains Academy en Hyperskill pueden ser un punto de partida perfecto. Toda la información y explicación de conceptos y técnicas se muestran en estos artículos. ¡No te los pierdas!
Estas pistas te brindarán experiencia práctica utilizando herramientas de vanguardia y te enseñarán cómo construir aplicaciones del lado del servidor, asegurar el almacenamiento persistente de datos en bases de datos y probar de manera efectiva la funcionalidad de tus aplicaciones utilizando herramientas modernas.
Te animamos a dejar cualquier pregunta o comentario en la sección de comentarios debajo de esta publicación del blog. Además, puedes seguirnos en plataformas de redes sociales como en Reddit (opens new window), Twitter (opens new window), LinkedIn (opens new window) y Facebook (opens new window) para estar informado sobre nuestros últimos artículos y proyectos.